Real-time Benchmarking#
This Reference Implementation will provide a step-by-step guide to benchmark a real-time capable system using micro benchmarks to test performance.
Benchmark Disclaimer#
Important
Performance varies by use, configuration and other factors. Learn more at https://intel.com/PerformanceIndex.
Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See configuration disclosure for details. No product or component can be absolutely secure.
Your costs and results may vary.
Intel technologies may require enabled hardware, software or service activation.
Benchmark Platforms#
Intel® Core™ i7-1185GRE Processor
Unless otherwise stated, results obtained for the Intel® Core™ i7-1185GRE Processor were performed on the following system:
Manufacturer
Vecow*
MPN
SPC-7100
Processor
Intel® Core™ i7-1185GRE Processor
1.8 GHz to 4.4 GHz
15W TDP
Memory
32 GB DDR4
OS
Intel Atom® x6425RE Processor
Unless otherwise stated, results obtained for the Intel Atom® x6425RE Processor were performed on the following system:
Manufacturer
ASRock*
MPN
Processor
Intel Atom® x6425RE Processor
1.9 GHz
12W TDP
Memory
16 GB DDR4
OS
Prerequisites#
To properly execute this Reference Implementation, your system should meet the following requirements:
Specification |
Requirement |
|---|---|
BIOS |
Configured to disable processor power and frequency modulation |
Linux kernel |
Real-time Linux kernel |
Linux kernel boot parameters |
Core isolation and real-time features |
See also
See Setting Up An Optimized Intel-Based Linux Real-Time Capable Edge System for a Reference Implementation to achieving a real-time capable system.
Setup Package Repository#
![]()
![]()
Setup the ECI APT repository:
Download the ECI APT key to the system keyring:
$ sudo -E wget -O- https://eci.intel.com/repos/gpg-keys/GPG-PUB-KEY-INTEL-ECI.gpg | sudo tee /usr/share/keyrings/eci-archive-keyring.gpg > /dev/null
Add the signed entry to APT sources and configure the APT client to use the ECI APT repository:
$ echo "deb [signed-by=/usr/share/keyrings/eci-archive-keyring.gpg] https://eci.intel.com/repos/$(source /etc/os-release && echo $VERSION_CODENAME) isar main" | sudo tee /etc/apt/sources.list.d/eci.list $ echo "deb-src [signed-by=/usr/share/keyrings/eci-archive-keyring.gpg] https://eci.intel.com/repos/$(source /etc/os-release && echo $VERSION_CODENAME) isar main" | sudo tee -a /etc/apt/sources.list.d/eci.list
Configure the ECI APT repository to have higher priority over other repositories:
$ sudo bash -c 'echo -e "Package: *\nPin: origin eci.intel.com\nPin-Priority: 1000" > /etc/apt/preferences.d/isar'
Update the APT sources lists:
$ sudo apt update
Tip
If the APT package manager is unable to connect to the repositories, follow these APT troubleshooting tips:
Make sure that the system has network connectivity.
Make sure that the ports
80and8080are not blocked by a firewall.Configure an APT proxy (if network traffic routes through a proxy server). To configure an APT proxy, add the following lines to a file at
/etc/apt/apt.conf.d/proxy.conf(replace the placeholders as per your specific user and proxy server):Acquire::http::Proxy "http://user:password@proxy.server:port/"; Acquire::https::Proxy "http://user:password@proxy.server:port/";
![]()
Setup the ECI DNF repository:
Use the
config-managertool to add the ECI DNF repository to the system:$ sudo dnf config-manager --add-repo https://eci.intel.com/repos/rhel/eci-el9.repo
Verify the ECI DNF repository was correctly added. Run the following command and verify that the ECI DNF repository
eci-el#-rpm-*are present:$ dnf repolist
repo id repo name eci-el9-rpm-x86_64 Intel Edge Controls for Industrial - EL9 (x86_64) eci-el9-rpm-noarch Intel Edge Controls for Industrial - EL9 (noarch)
Some of the ECI packages depend on additional DNF repositories, specifically Extra Packages for Enterprise Linux (EPEL). Configure the DNF package manager with these additional DNF repositories:
$ sudo dnf install -y https://dl.fedoraproject.org/pub/epel/epel-release-latest-9.noarch.rpm
Install Benchmark Suite#
Perform either of the following commands to install this component:
![]()
![]()
$ sudo apt install eci-realtime-benchmarking
![]()
$ sudo dnf install eci-realtime-benchmarking
48-Hour Benchmark#
Benchmark |
Units |
Version |
Source |
|---|---|---|---|
48-Hour Benchmark |
(see respective benchmark) |
1.4 |
Intel® created |
The 48-Hour Benchmark exercises the Caterpillar and Cyclictest Workload benchmarks with and without Cache Allocation Technology to demonstrate the benefits of Cache Allocation Technology on real-time workloads.
The 48-Hour Benchmark exercises the following tests and configurations:
- Test 1:
Benchmark: Caterpillar
Benchmark Affinity: first isolated core (typically core 1)
Benchmark Priority:
chrt -f 95Noisy Neighbor:
stress-ngmemcpyNoisy Neighbor Affinity: first non-isolated core (typically core 0)
Duration: ~3 hours
Cache Allocation Technology Enabled: No
- Test 2:
Benchmark: Caterpillar
Benchmark Affinity: first isolated core (typically core 1)
Benchmark Priority:
chrt -f 95Noisy Neighbor:
stress-ngmemcpyNoisy Neighbor Affinity: first non-isolated core (typically core 0)
Duration: ~3 hours
Cache Allocation Technology Enabled: Yes (
COS0=0x0f→ non-isolated cores (typically 0,2),COS1=0xf0→ first isolated core (typically core 1)
- Test 3:
Benchmark: Cyclictest Workload with interval of 250μs
Benchmark Affinity: first isolated core (typically core 1)
Benchmark Priority:
chrt -f 95Noisy Neighbor:
stress-ngmemcpyNoisy Neighbor Affinity: first non-isolated core (typically core 0)
Duration: 24 hours
Cache Allocation Technology Enabled: No
- Test 4:
Benchmark: Cyclictest Workload with interval of 250μs
Benchmark Affinity: first isolated core (typically core 1)
Benchmark Priority:
chrt -f 95Noisy Neighbor:
stress-ngmemcpyNoisy Neighbor Affinity: first non-isolated core (typically core 0)
Duration: 24 hours
Cache Allocation Technology Enabled: Yes (
COS0=0x0f→ non-isolated cores (typically 0,2),COS1=0xf0→ first isolated core (typically core 1)
Execute 48-Hour Benchmark#
To start the benchmark, run the following command:
$ /opt/benchmarking/mega-benchmark/48_hour_benchmark.sh
Results are logged to the files named: results_48_hour_benchmark_<date>, caterpillar_without_cat.log, and caterpillar_with_cat.log.
Interpret 48-Hour Benchmark Results#
Since the 48-Hour Benchmark comprises a subset of benchmarks, refer to the respective benchmark sections:
Example of 48-Hour Benchmark Data#
The following configurations were used:
- Caterpillar without Cache Allocation Technology
Benchmark: Caterpillar
Benchmark Affinity: Core 3
Benchmark Priority:
chrt 99Noisy Neighbor:
stress-ngmemcpyNoisy Neighbor Affinity: 0
Duration: ~3 hours
Cache Allocation Technology Enabled: No
- Caterpillar with Cache Allocation Technology
Benchmark: Caterpillar
Benchmark Affinity: Core 3
Benchmark Priority:
chrt 99Noisy Neighbor:
stress-ngmemcpyNoisy Neighbor Affinity: Core 0
Duration: ~3 hours
Cache Allocation Technology Enabled: Yes (
COS0=0x0f→ Cores 0-2,COS3=0xf0→ Core 3)
- Cyclictest without Cache Allocation Technology
Benchmark: Cyclictest Workload with interval of 250μs
Benchmark Affinity: Core 3
Benchmark Priority:
chrt 99Noisy Neighbor:
stress-ngmemcpyNoisy Neighbor Affinity: Core 0
Duration: 24 hours
Cache Allocation Technology Enabled: No
- Cyclictest with Cache Allocation Technology
Benchmark: Cyclictest Workload with interval of 250μs
Benchmark Affinity: Core 3
Benchmark Priority:
chrt 99Noisy Neighbor:
stress-ngmemcpyNoisy Neighbor Affinity: Core 0
Duration: 24 hours
Cache Allocation Technology Enabled: Yes (
COS0=0x0f→ Cores 0-2,COS1=0xf0→ Core 3)
Intel® Core™ i7-1185GRE Processor - Caterpillar#
See also
See section Caterpillar for more information about this benchmark.
![]()
This benchmark data was collected on eci-image-ubuntu in a native environment.
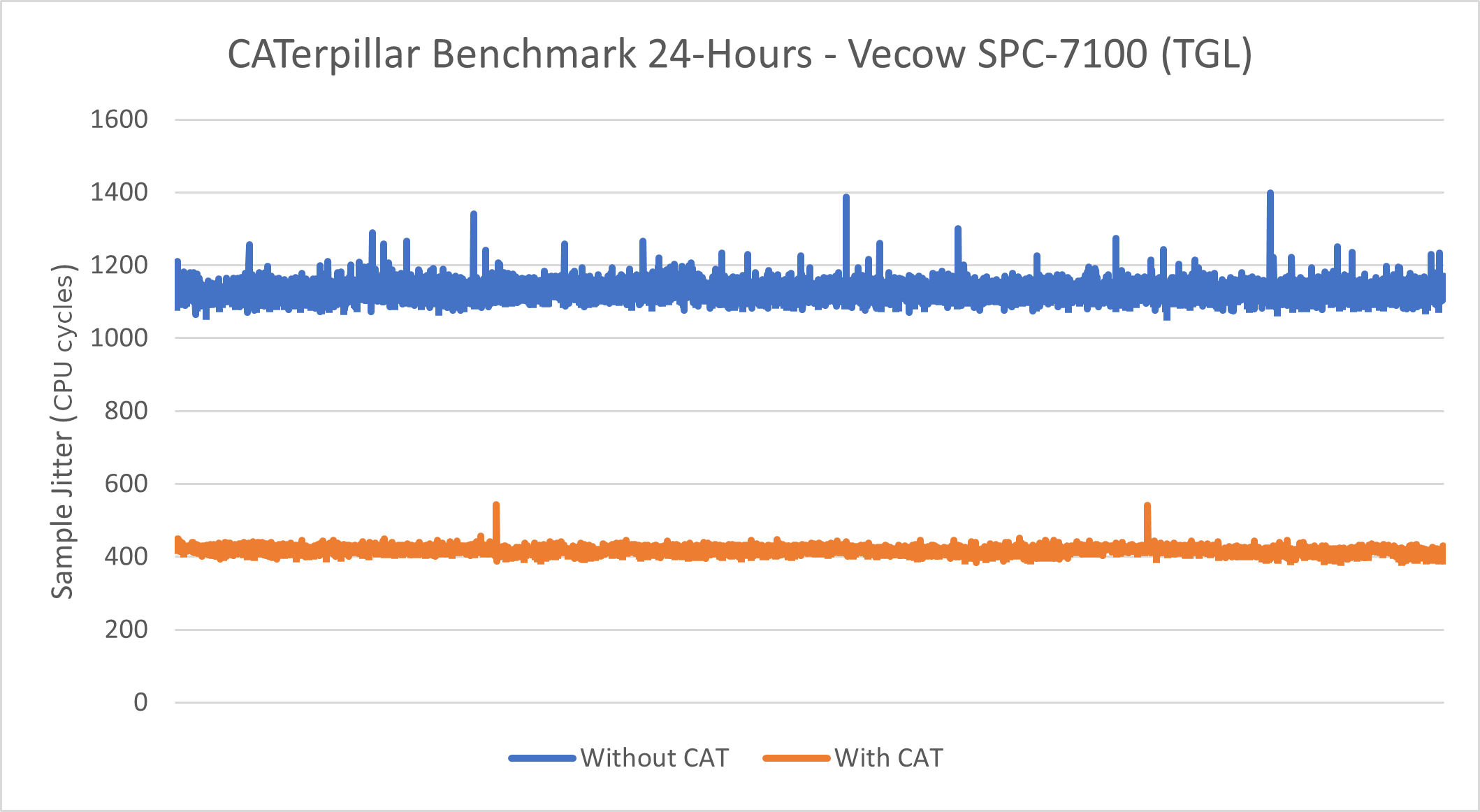
Without CAT |
With CAT |
|
|---|---|---|
Minimum Sample Jitter (CPU Cycles) |
1062 |
385 |
Maximum Sample Jitter (CPU Cycles) |
1398 |
543 |
Standard Deviation (CPU Cycles) |
21.89 |
8.89 |
Intel® Atom x6425RE Processor - Caterpillar#
See also
See section Caterpillar for more information about this benchmark.
![]()
This benchmark data was collected on eci-image-ubuntu in a native environment.
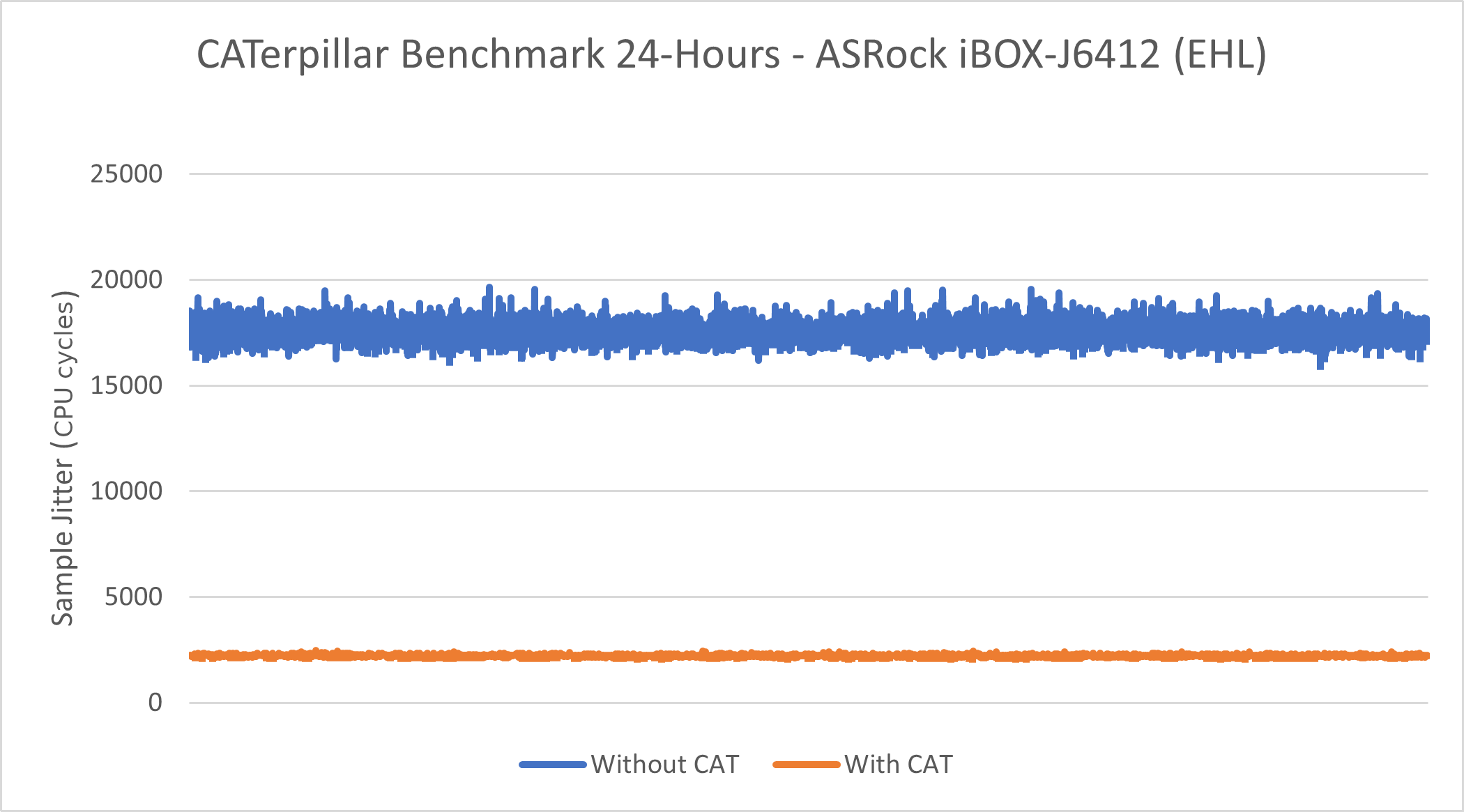
Without CAT |
With CAT |
|
|---|---|---|
Minimum Sample Jitter (CPU Cycles) |
15958 |
2109 |
Maximum Sample Jitter (CPU Cycles) |
19658 |
2490 |
Standard Deviation (CPU Cycles) |
446.09 |
31.29 |
Intel® Core™ i7-1185GRE Processor - Cyclictest#
See also
See section Cyclictest Workload for more information about this benchmark.
![]()
This benchmark data was collected on eci-image-ubuntu in a native environment.
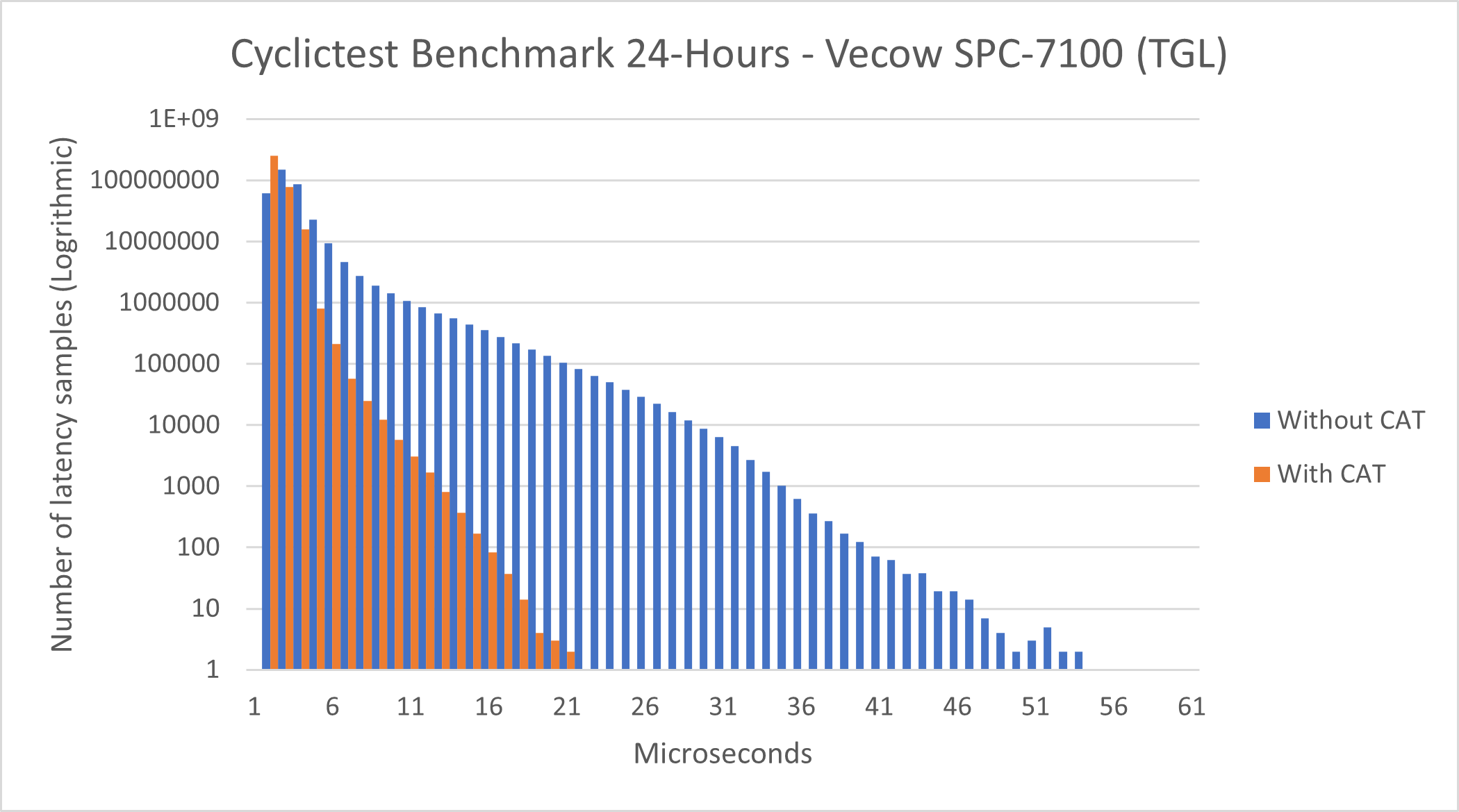
Without CAT |
With CAT |
|
|---|---|---|
Total Samples |
345600000 |
345600000 |
Minimum Latencies (μs) |
00001 |
0000` |
Average Latencies (μs) |
00002 |
00001 |
Maximum Latencies (μs) |
00055 |
00022 |
Intel® Atom x6425RE Processor - Cyclictest#
![]()
This benchmark data was collected on eci-image-ubuntu in a native environment.
See also
See section Cyclictest Workload for more information about this benchmark.
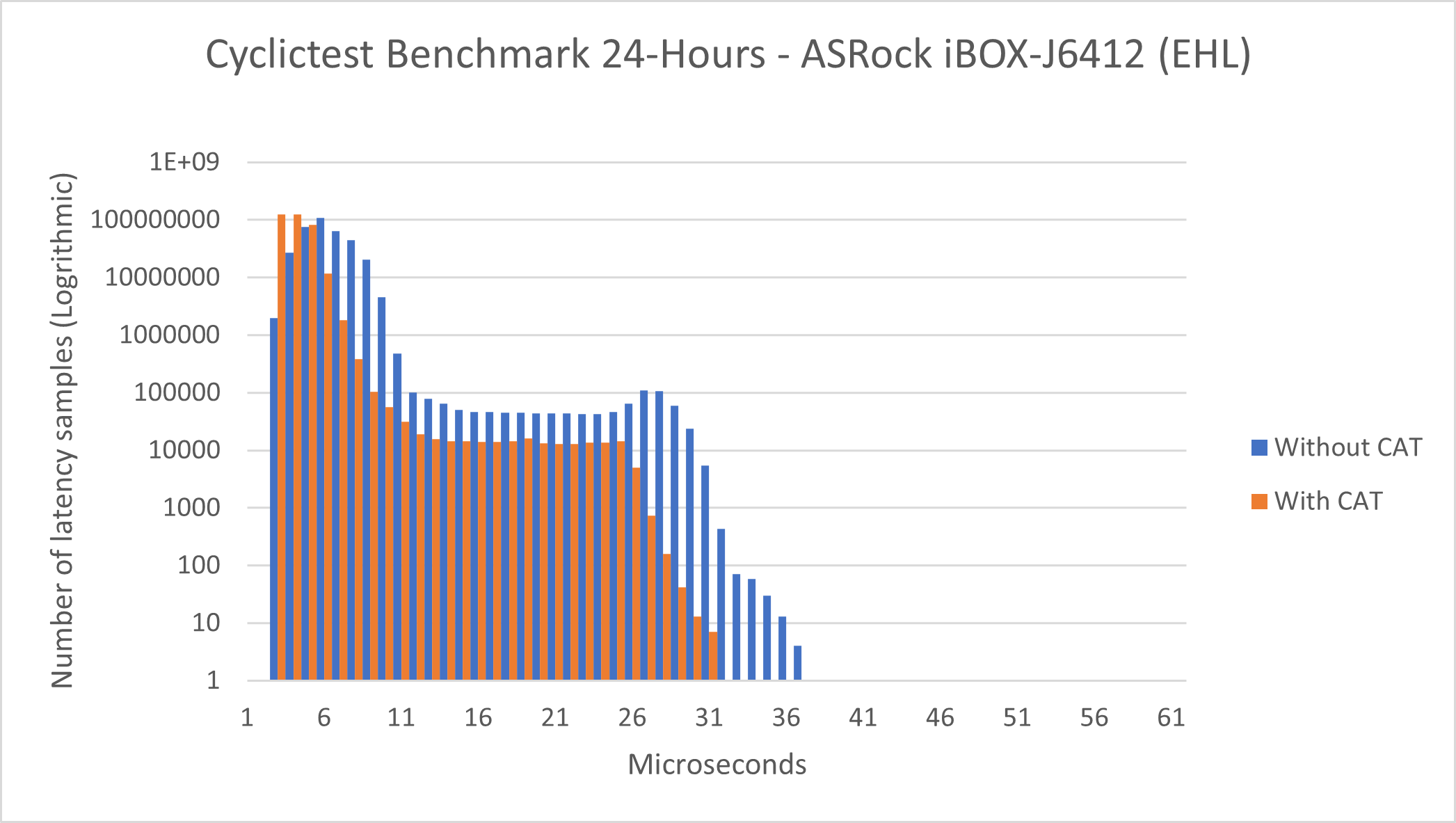
Without CAT |
With CAT |
|
|---|---|---|
Total Samples |
345600000 |
345600000 |
Minimum Latencies (μs) |
00002 |
00002 |
Average Latencies (μs) |
00005 |
00002 |
Maximum Latencies (μs) |
00036 |
00036 |
Mega Benchmark#
Benchmark |
Units |
Version |
Source |
|---|---|---|---|
Mega Benchmark |
(see respective benchmark) |
1.4 |
Intel® created |
The mega-benchmark exercises the following tests:
Rhealstone xLatency
Rhealstone stress test
Execute Mega Benchmark#
To start the benchmark, run the following command:
$ /opt/benchmarking/mega-benchmark/mega_benchmark.sh
Results are logged to a file named: results_mega_benchmark_<date>
Interpret Mega Benchmark Results#
Since the Mega Benchmark comprises a subset of benchmarks, refer to the respective benchmark sections:
Cyclictest Workload#
Benchmark |
Units |
Version |
Source |
|---|---|---|---|
Cyclictest |
microseconds |
2.4 Debian 12 (Bookworm) / 2.5 Canonical® Ubuntu® 24.04 (Noble Numbat) |
https://git.kernel.org/pub/scm/utils/rt-tests/rt-tests.git/snapshot/rt-tests-1.5.tar.gz |
Cyclictest is most commonly used for benchmarking real-time (RT) systems. It is one of the most frequently used tools for evaluating the relative performance of an RT. Cyclictest accurately and repeatedly measures the difference between a thread’s intended wake-up time and the time at which it actually wakes up to provide statistics about the system’s latency. It can measure latency in real-time systems caused by the hardware, the firmware, and the operating system.
Execute Cyclictest Workload#
An example script that runs the cyclictest benchmark and the README is available at /opt/benchmarking/rt-tests. The script performs the following runtime optimizations before executing the benchmark:
Assigns benchmark thread affinity to last isolated core (typically core 3)
Assigns non-benchmark thread affinity to core 0
Changes the priority of benchmark thread to 95 (using:
chrt -f 95)Disables kernel machine check interrupt
Increases thread runtime utilization to infinity
To start the benchmark, run the following command:
$ sudo /opt/benchmarking/rt-tests/start-cyclic.py
Default parameters are used unless otherwise specified. Run the script with --help to list the modifiable arguments.
Interpret Cyclictest Results#
Short |
Explanation |
|---|---|
T |
Thread: Thread index and thread ID |
P |
Priority: RT thread priority |
I |
Interval: Intended wake up period for the latency measuring threads |
C |
Count: Number of times the latency was measured that is, iteration count |
Min |
Minimum: Minimum latency that was measured |
Act |
Actual: Latency measured during the latest completed iteration |
Avg |
Average: Average latency that was measured |
Max |
Maximum: Maximum latency that was measured |
On a non-realtime system, the result might be similar to the following:
T: 0 ( 3431) P:99 I:1000 C: 100000 Min: 5 Act: 10 Avg: 14 Max: 39242
T: 1 ( 3432) P:98 I:1500 C: 66934 Min: 4 Act: 10 Avg: 17 Max: 39661
The right-most column contains the most important result, that is, the worst-case latency of 39.242 ms / 39242 us (Max value).
On a realtime-enabled system, the result might be similar to the following:
T: 0 ( 3407) P:99 I:1000 C: 100000 Min: 7 Act: 10 Avg: 10 Max: 18
T: 1 ( 3408) P:98 I:1500 C: 67043 Min: 7 Act: 8 Avg: 10 Max: 22
This result indicates an apparent short-term worst-case latency of 18 us. According to this, it is important to pay attention to the Max values as these are indicators of outliers. Even if the system has decent Avg (average) values, a single outlier as indicated by Max is enough to break or disturb a real-time system.
According to the README from the https://git.kernel.org/pub/scm/utils/rt-tests/rt-tests.git repository:
Running cyclictest only over a short period of time and without creating appropriate real-time stress conditions is rather meaningless, since the execution of an asynchronous event from idle state is normally always quite fast, and every - even non-RT system - can do that. The challenge is to minimize the latency when reacting to an asynchronuous event, irrespective of what code path is executed at the time when the external event arrives. Therefore, specific stress conditions must be present while cyclictest is running to reliably determine the worst-case latency of a given system.
Additional Cyclictest Workload#
Another script, rt_bmark.py, performs stress workloads when executing the benchmark cyclictest.
To start the benchmark, run the following command:
$ sudo /opt/benchmarking/rt-tests/rt_bmark.py
Hardware Latency Detector#
Benchmark |
Units |
Version |
Source |
|---|---|---|---|
Hardware Latency Detector |
N/A |
0.8 |
https://git.kernel.org/pub/scm/utils/rt-tests/rt-tests.git/snapshot/rt-tests-1.5.tar.gz |
Execute Hardware Latency Detector#
To start the benchmark, run the following command:
$ sudo touch /dev/cpu_dma_latency
$ sudo hwlatdetect --threshold=1us --duration=1m --window=1000ms --width=950ms --report=hwlat.log
Default parameters are used. Run the command with --help to list the modifiable arguments.
Note
It has been observed that hwlatdetect will sometimes fail to capture any samples when more than one efficiency core is enabled. If you encounter this situation, you can offline the efficiency cores, conduct the benchmark, then online the cores again using these commands:
# Offline all efficiency cores (atom type)
$ for i in $(sudo cat /sys/devices/cpu_atom/cpus | perl -pe 's/(\d+)-(\d+)/join(" ",$1..$2)/eg'); do echo 0 | sudo tee /sys/devices/system/cpu/cpu$i/online ; done
# Execute benchmark
$ sudo hwlatdetect --threshold=1us --duration=1m --window=1000ms --width=950ms --report=hwlat.log
# Online any offlined cores
$ for i in $(sudo cat /sys/devices/system/cpu/offline | perl -pe 's/(\d+)-(\d+)/join(" ",$1..$2)/eg'); do echo 1 | sudo tee /sys/devices/system/cpu/cpu$i/online ; done
Interpret Hardware Latency Detector Results#
hwlatdetect: test duration 172800 seconds
detector: tracer
parameters:
Latency threshold: 1us
Sample window: 1000000us
Sample width: 950000us
Non-sampling period: 50000us
Output File: hwlat.log
Starting test
test finished
Max Latency: 8509us
Samples recorded: 12
Samples exceeding threshold: 12
3 SMIs occured on cpu 0
3 SMIs occured on cpu 1
3 SMIs occured on cpu 2
3 SMIs occured on cpu 3
3 SMIs occured on cpu 4
3 SMIs occured on cpu 5
3 SMIs occured on cpu 6
3 SMIs occured on cpu 7
SMIs during run: 24
report saved to hwlat.log (12 samples)
ts: 1716179830.249172536, inner:0, outer:8509
ts: 1716181519.723242206, inner:0, outer:13
ts: 1716194771.846998020, inner:6, outer:3
ts: 1716265958.875256655, inner:12, outer:11
ts: 1716277767.975081358, inner:0, outer:4
ts: 1716286007.859183873, inner:8, outer:0
ts: 1716296995.882698754, inner:9, outer:0
ts: 1716308068.834712777, inner:0, outer:2
ts: 1716313762.634791257, inner:0, outer:6
ts: 1716323403.043182533, inner:0, outer:6
ts: 1716339459.875197056, inner:13, outer:11
ts: 1716340021.026991303, inner:4, outer:1
The benchmark results of hwlatdetect mainly includes the following parts:
SMI counts occurred during benchmark through reading MSR.
Sample recorded during benchmark.
hwlatdetect detects the highest latency value in a sample window within sample width and checks if it exceeds the threshold. If the highest value exceeds the threshold, hwlatdetect records the sample in the log. Every sample record in the log consists of three parameters: ts, inner and outer. These parameters are described below:
ts(Unit: second): The timestamp of the sample recorded based on real-time clock.inner(Unit: microsecond): The latency between two consecutive reads for timestamp.outer(Unit: microsecond): The latency between two consecutive loops for sampling the hardware latency.
Jitter#
Benchmark |
Units |
Version |
Source |
|---|---|---|---|
Jitter |
CPU Cycles |
1.9 |
Intel® created |
The Jitter benchmark measures the execution time variation of a CPU test workload. The performance of the workload is impacted by kernel interrupts. Minimizing these interrupts also minimizes the jitter that applications could potentially experience.
Execute Jitter#
An example script that runs the Jitter benchmark is available at /opt/benchmarking/jitter/start-benchmark.py. The script performs the following runtime optimizations before executing the benchmark:
Assigns benchmark thread affinity to last isolated core (typically core 3)
Assigns non-benchmark thread affinity to first non-isolated core (typically core 0)
Changes the priority of benchmark thread to 95 (using:
chrt -f 95)Disables kernel machine check interrupt
Increases thread runtime utilization to infinity
Starts a “noisy neighbor” on an adjacent core using
stress-ng --cpu 1 --memcpy
To assess the impact of Cache Allocation Technology, it is useful to perform the benchmark with and without Cache Allocation Technology enabled. The two examples below provide a method of achieving this.
The first step is to establish a baseline performance to compare against. Start the benchmark without Cache Allocation Technology. Take note of the
Inst_Jittervalue, since indicates the execution jitter in CPU cycles experienced by the benchmark.$ test_core=$(cat /sys/devices/system/cpu/isolated | cut -d '-' -f1 | cut -d ',' -f1) $ sudo /opt/pqos/pqos-helper.py --cos0 0xff --assign_cos "0=0 0=1 0=2 0=3" --pqos_rst --pqos_msr --command "/opt/benchmarking/jitter/start-benchmark.py --jitter_args '-c ${test_core:-1}'"
Now, start the benchmark with Cache Allocation Technology. The pqos-helper tool is being used here to partition the CPU cache and isolate the cache used by the benchmark. Note how only core 1 is assigned to Class of Service (COS) 1, and the only task executing on core 1 will be the benchmark. This cache configuration should reduce cache evictions experienced by the benchmark caused by the “noisy neighbor”, resulting in reduced execution jitter.
$ test_core=$(cat /sys/devices/system/cpu/isolated | cut -d '-' -f1 | cut -d ',' -f1) $ sudo /opt/pqos/pqos-helper.py --cos0 0x0f --cos1 0xf0 --assign_cos "0=0 0=1 0=2 1=${test_core:-1}" --pqos_rst --pqos_msr --command "/opt/benchmarking/jitter/start-benchmark.py --jitter_args '-c ${test_core:-1}'"
Compare the results of the two runs. Ideally, the run with Cache Allocation Technology enabled should exhibit lower execution jitter.
Default parameters are used unless otherwise specified. Run the script with --help to list the modifiable arguments.
Interpret Jitter Results#
Inst_Min Inst_Max Inst_jitter last_Exec Abs_min Abs_max tmp Interval Sample No
177205 235598 58393 177219 164702 243978 1227096064 3604948177 200 66777
The most important measurement is Inst_jitter. This measurement describes the execution jitter (in CPU cycles) during the display update interval. It is desired that Inst_jitter be as low as possible. The delta between Abs_max and Abs_min is the overall jitter spread. Ideally, the spread must be as low as possible.
Caterpillar#
Benchmark |
Units |
Version |
Source |
|---|---|---|---|
Caterpillar |
CPU Cycles |
1.3 |
Intel® created |
The Caterpillar benchmark measures the execution time variation of a memory test workload. The performance of the workload is impacted by cache misses. Using Cache Allocation Technology improves application performance by assigning CPU affinity to cache ways, which can be dedicated to real-time applications.
Execute Caterpillar#
An example script running the Caterpillar benchmark is available at /opt/benchmarking/caterpillar/start-benchmark.py. The script performs the following runtime optimizations before executing the benchmark:
Assigns benchmark thread affinity to last isolated core (typically core 3)
Assigns non-benchmark thread affinity to first non-isolated core (typically core 0)
Changes the priority of benchmark thread to 95 (using:
chrt -f 95)Disables kernel machine check interrupt
Increases thread runtime utilization to infinity
Starts a “noisy neighbor” on an adjacent core using
stress-ng --cpu 1 --memcpy
To assess the impact of Cache Allocation Technology, it is useful to perform the benchmark with and without Cache Allocation Technology enabled. The two examples below provide a method of achieving this.
The first step is to establish a baseline performance to compare against. Start the benchmark without Cache Allocation Technology by assigning cores 0-3 the same class of service. Take note of the
SmplJittervalue, since indicates the execution jitter in CPU cycles experienced by the benchmark.$ test_core=$(cat /sys/devices/system/cpu/isolated | cut -d '-' -f1 | cut -d ',' -f1) $ sudo /opt/pqos/pqos-helper.py --cos0 0xff --assign_cos "0=0 0=1 0=2 0=3" --pqos_rst --pqos_msr --command "/opt/benchmarking/caterpillar/start-benchmark.py --caterpillar_args '-c ${test_core:-1}'"
Now, start the benchmark with Cache Allocation Technology. The pqos-helper tool is being used here to partition the CPU cache and isolate the cache used by the benchmark. Note how only core 1 is assigned to Class of Service (COS) 1, and the only task executing on core 1 will be the benchmark. This cache configuration should reduce cache evictions experienced by the benchmark caused by the “noisy neighbor”, resulting in reduced execution jitter.
$ test_core=$(cat /sys/devices/system/cpu/isolated | cut -d '-' -f1 | cut -d ',' -f1) $ sudo /opt/pqos/pqos-helper.py --cos0 0x0f --cos1 0xf0 --assign_cos "0=0 0=1 0=2 1=${test_core:-1}" --pqos_rst --pqos_msr --command "/opt/benchmarking/caterpillar/start-benchmark.py --caterpillar_args '-c ${test_core:-1}'"
Compare the results of the two runs. Ideally, the run with Cache Allocation Technology enabled should exhibit lower execution jitter.
Default parameters are used unless otherwise specified. You may run the script with --help to list the modifiable arguments.
Interpret Caterpillar Results#
SampleMin SampleMax SmplJitter SessionMin SessionMax SessionJitter Sample
254023 300255 9649 233516 303071 9743 200
The most important measurement is SessionJitter. This measurement describes the maximum execution jitter (in CPU cycles) during the entire execution of the benchmark. It is desired that SessionJitter be as low as possible. The delta between SessionMax and SessionMin is the overall execution spread. Ideally, the spread must be as low as possible.
Rhealstone#
Benchmark |
Units |
Version |
Source |
|---|---|---|---|
Rhealstone |
nanoseconds |
1.2 |
https://gitlab.denx.de/Xenomai/xenomai/tree/master/testsuite/latency |
Rhealstone is a measurement targeted specifically toward true multitasking solutions. In this benchmark, five categories of activities crucial to the performance of real-time systems are represented:
Task switching time
Preemption time
Semaphore shuffling time
Interrupt latency time
Deadlock breaking time
Execute Rhealstone#
Two example scripts that run the Rhealstone benchmark are available at /opt/benchmarking/(rhealstone|rhealstone-xenomai). The script run_xlatency.py performs the following runtime optimizations before executing the benchmark latency:
Assigns benchmark thread affinity to core 0
Assigns non-benchmark thread affinity to core 1, as stress workloads.
Dumps histogram to <file> in a format easily readable with
gnuplotPrints statistics of minimum, average, and maximum latencies
Sets sampling period to 250 us
To start the benchmark, run the following script:
//without stress
$ cd /opt/benchmarking/rhealstone
$ sudo ./run_xlatency.py -T <runtime>
//with stress
$ cd /opt/benchmarking/rhealstone
$ sudo ./run_xlatency.py -T <runtime> --stress
//with stress exclude gfx for image without glxgears
$ cd /opt/benchmarking/rhealstone
$ sudo ./run_xlatency.py -T <runtime> --stress --no-gfx
Command line parameters:
runtime: Set test period in seconds.
Default parameters are used unless otherwise specified. Run the script with --help to list the modifiable arguments. Otherwise, run the latency benchmark directly with --help to list the modifiable arguments.
The script run_rhealstone_bmark.py executes benchmarks ctx_lat, deadlock_bt, preempt_lat, and semaphore_lat separately for <num> times and gets the average result for each.
To start the benchmark, run the following command:
$ cd /opt/benchmarking/rhealstone
$ sudo ./run_rhealstone_bmark.py <num>
Interpret Rhealstone Results#
The results obtained from run_xlatency.py are measured interrupt latency. Lower values are better.
...
#Avg: 0.683 us
#Max: 4.656 us
#Max list: [4.656]
...
The results obtained from run_rhealstone_bmark.py are measured time to perform: task switching, preemption, semaphore shuffling, and deadlock breaking. Lower values are better.
// Task Switching
#ctx_sum is 84878.48
#ctx_avg is 848.78
// Deadlock Breaking
#dead_sum is 225127.860003
#dead_avg is 2251.278600
// Preemption
#pree_sum is 114065.000000
#pree_avg is 1140.650000
// Semaphore Shuffling
#sem_sum is 208111.365000
#sem_avg is 2081.113650
MSI Latency#
Benchmark |
Units |
Version |
Source |
|---|---|---|---|
MSI Latency |
nanoseconds |
1.6.0-k |
Intel® created |
Message Signaled Interrupt (MSI) Latency measures interrupt latency for MSIs generated by a discrete or integrated peripheral device, such as the Intel® I210/I225/I226 Ethernet Controller Series and serviced by the IA core. This benchmark measures the MSI interrupt triggered back latency of Intel® I210/I225/I226 Ethernet Controller Series kernel module.
Attention
This benchmark only functions in tandem with an Intel® I210/I225/I226 Ethernet Controller.
Execute MSI Latency#
An example script that runs the MSI latency benchmark is available at /opt/benchmarking/msi-latency. The script performs the following runtime optimizations before executing the benchmark:
Moves all IRQs (except timer and cascade) to core 0
Moves all rcu tasks to either core 0, 4, 5, 6, 7, except 1-3
Changes the real-time attributes of all rcu tasks to
SCHED_OTHERand priority 0Changes the real-time attributes of all tasks on core 1, 2 and 3 to
SCHED_OTHERand priority 0Changes the real-time attributes of all tasks to
SCHED_OTHERand priority 0
Required kernel boot parameters:
isolcpus=1,3 rcu_nocbs=1,3 nohz_full=1,3 igb.blacklist=yes
To start the benchmark, run the following commands:
$ cd /opt/benchmarking/msi-latency
$ sudo ./msiLatencyTest.sh <coreSpecIRQ> <irqPeriod> <irqCount>
$ cat /sys/kernel/debug/msi_latency_test/current_value # Get current result
Default parameters are used when insert msi_lat.ko, unless otherwise specified. Command line parameters:
Parameter
Description
coreSpecIRQCore on which the
msi_latencytest IRQ handler is run. [0 to n]
coreSpecWQCore on which the
msi_latencytest work queue is run. [0 to n]
irqSpecRun IRQ as a pthread [0] or in legacy mode [1].
irqPeriodPeriod between interrupts in milliseconds.
irqCountNumber of IRQs to send. n > 0 will be finite. n < 0 will be infinite.
verbosityVerbosity of periodic prints to
dmesg. [0 to 3]
offsetStartOffset that is subtracted from each starting timestamp when calculating latency and generating histogram buckets (does not effect raw values). Mechanism used to remove delta time (nanosecond) from when SW requests interrupt to HW services interrupt.
blockIRQDuration (clock ticks) for which the interrupts are blocked after requesting MSI.
Interpret MSI Latency Results#
************ RESULTS (ns) ************
[15996.755567] * Max: 9056
[15996.755570] * Avg: 6626
[15996.755573] * Min: 5360
The reported value is the measured time to service MSI requests to the Intel® I210/I225/I226 Ethernet Controller. Lower values are better.
MSI Jitter#
Benchmark |
Units |
Version |
Source |
|---|---|---|---|
MSI Jitter |
nanoseconds |
1.3.0-m |
Intel® created |
MSI jitter benchmark tool is a benchmark tool to check the jitter of cyclical MSI from an Intel® I210/I225/I226 Ethernet Controller. This tool records each cyclical MSI timestamps in the software interrupt handler and calculates the delta between each timestamps and compares the delta with cycle time as the jitter.
Attention
This benchmark only functions in tandem with an Intel® I210/I225/I226 Ethernet Controller.
Execute MSI Jitter#
An example script that runs the MSI latency benchmark is available at /opt/benchmarking/msi-jitter. The script performs the following runtime optimizations before executing the benchmark:
Moves all IRQs (except timer and cascade) to core 0
Moves all rcu tasks to either core 0, 4, 5, 6, 7, except 1-3
$ sudo /opt/benchmarking/msi-jitter/irq_rcu.sh
To start the benchmark, run the following commands:
$ cd /opt/benchmarking/msi-jitter
$ sudo ./run_msijitter.sh <unbind_igb_id> <run_core> <interval(ms)> <runtime(s)>
$ cat /sys/kernel/debug/msi_jitter_test/current_value # Get current result
Command line parameters:
unbind_igb_id: PCI ID of NIC to unbind.
Can find PCI ID with: `lspci -v | grep -Ei 'Ethernet controller: Intel Corporation.*'`.
run_core: Set which core will handle MSI interrupt.
interval: Set cycle time.
runtime: Set test period.
Interpret MSI Jitter Results#
************ RESULTS (ns) ************
[ 4177.021407] * Max: 3184
[ 4177.023363] * Avg: 222
[ 4177.025218] * Min: 0
The reported value is the measured jitter of servicing MSI requests to the Intel® I210/I225/I226 Ethernet Controller. Lower values are better.
MMIO Latency#
Benchmark |
Units |
Version |
Source |
|---|---|---|---|
MMIO Latency |
nanoseconds |
1.1 |
Intel® created |
MMIO-latency is a simple driver that creates an affinitized thread to read a virtual map physical address (Memory-mapped I/O). Memory read latency is measured. The thread is created and started on initialization and loops LOOPS number of times. It also provides a char device that reads the current statistic counters, by using inline assembly and kernel function to get a very close benchmark.
Execute MMIO Latency#
An example script that runs the MSI latency benchmark is available at /opt/benchmarking/mmio-latency. The script performs the following runtime optimizations before executing the benchmark:
Moves all IRQs (except timer and cascade) to core 0
Moves all rcu task to either core 0, 4, 5, 6, 7, except 1-3
Changes realtime attributes of all rcu tasks to
SCHED_OTHERand priority 0Changes realtime attributes of all tasks on core 1, 2 and 3 to
SCHED_OTHERand priority 0Changes realtime attributes of all tasks to
SCHED_OTHERand priority 0
To start the benchmark, run the following command:
$ sudo /opt/benchmarking/mmio-latency/mmioLatency.sh <MMIO_address> <block_irq(1 or 0)>
Default parameters are used unless otherwise specified.
Find the physical mmio address to test using the command: lspci -vvv -s $BDF.
For example:
$ lspci -nn ==> 00:02.0 SATA controller
$ lspci -vvv -s 00:02.0 ==> Region 0: Memory at 80002000
Interpret MMIO Latency Results#
RT Core Module
------------------------
Stats:
max= 6472
avg= 2814
min= 588
total= 973791140
loops= 346010
mmio-outliers: 247
sched-outliers: 9
The reported value is the latency in reading memory-mapped I/O. Lower values are better.
Real-Time Performance Measurement (RTPM)#
Benchmark |
Units |
Version |
Source |
|---|---|---|---|
RTPM |
(See respective benchmark) |
1.11 |
Intel® created |
About RTPM#
Real-time computing is critical to industrial usage scenarios. Intel® real-time solutions focus on hard real-time use cases where there could be capability failures if the solutions are not executed within the allotted time span. Examples of the usage scenarios include robotics, automotive, and so on.
In a real-time computing system, several factors could impact the latency of reaction to the trigger event. These factors include hardware design, BIOS configuration, OS kernel configuration, system settings, and so on. RTPM is designed to check the key settings of the system and help you to identify the hot-spot of the system for real-time performance and provide a recommendation based on the Best-known Configuration (BKC). In addition, RTPM provides a way to measure the system scheduling latency with some open source tools.
RTPM Prerequisites#
RTPM depends on a specific version of the Cyclictest Workload. Perform the following steps to build and install this specific version:
Install necessary build dependencies:
$ sudo apt update $ sudo apt install -y usbutils unzip python3-setuptools python3-psutil gnuplot pciutils dmidecode build-essential libnuma-dev git
Clone the
rt-testsGit repository:$ git clone https://git.kernel.org/pub/scm/utils/rt-tests/rt-tests.git
Build and install
rt-tests:$ cd rt-tests && git checkout v2.6 $ make all $ sudo make install
Create a symbolic link to the newly installed
cyclictestapplication:$ sudo ln -s /usr/local/bin/cyclictest /usr/bin/cyclictest
RTPM Test Modules#
Real-Time Readiness Check#
This module leverages one of the Intel® Time Coordinated Computing (Intel® TCC) Tools to check the many attributes that might affect real-time performance.
This module:
Verifies whether the system has a supported processor, BIOS, and OS
Checks for features, such as Intel® Turbo Boost Technology, Enhanced Intel® SpeedStep® Technology, and processor power-saving states, that might affect real-time performance
Reports CPU and GPU frequencies
Operates at the OS level
Boot Command Line Check#
This module checks the real-time OS boot command line parameters and recommends settings as per BKCs.
Interpreting Boot Command Line Check Results
=============================BOOT CMDLINE CHECK Mon Dec 1 00:00:00 UTC 2021=============================
----------------------------------------------------------------------------------------------------------------------------------------------------------
|CMDLINE ENTRY |CURRENT VALUE |BKC |
----------------------------------------------------------------------------------------------------------------------------------------------------------
|processor.max_cstate |0 |0 |
|intel_idle.max_cstate |0 |0 |
|clocksource |tsc |tsc |
|tsc |reliable |reliable |
|nmi_watchdog |0 |0 |
|nosoftlockup |nosoftlockup |nosoftlockup |
|intel_pstate |disable |disable |
|efi |runtime |runtime |
|nohalt |Missing |nohalt |
|nohz |Missing |nohz |
|irqaffinity |0 |0 |
|hugepages |Missing |1024 |
|cpufreq.off |Missing |1 |
|i915.enable_rc6 |Missing |0 |
|i915.enable_dc |Missing |0 |
|i915.disable_power_well |Missing |0 |
|mce |Missing |off |
|hpet |Missing |disable |
|numa_balancing |Missing |disable |
|nohz_full |1,3 |[xxxx] |
|isolcpus |1,3 |[xxxx] |
|rcu_nocbs |1,3 |[xxxx] |
----------------------------------------------------------------------------------------------------------------------------------------------------------
Boot cmdline check finished.
Kernel Configuration Check#
This module checks the real-time OS kernel configuration and recommends settings as per the best-known configurations.
Interpret Kernel Configuration Check Results
=============================KERNEL CONFIGURATION CHECK Mon Dec 1 00:00:01 UTC 2021=============================
Kernel config file: /boot/config-5.4.115-rt57-intel-pk-standard+
----------------------------------------------------------------------------------------------------------------------------------------------------------
|KERNEL CONFIG ENTRY |CURRENT VALUE |BKC |
----------------------------------------------------------------------------------------------------------------------------------------------------------
|CONFIG_SMP |CONFIG_SMP=y |CONFIG_SMP=y |
|CONFIG_PREEMPT_RCU |CONFIG_PREEMPT_RCU=y |CONFIG_PREEMPT_RCU=y |
|CONFIG_GENERIC_IRQ_MIGRATION |CONFIG_GENERIC_IRQ_MIGRATION=y |CONFIG_GENERIC_IRQ_MIGRATION=y |
|CONFIG_EXPERT |CONFIG_EXPERT=y |CONFIG_EXPERT=y |
|CONFIG_PCIE_PTM |CONFIG_PCIE_PTM=y |CONFIG_PCIE_PTM=y |
|CONFIG_EFI |CONFIG_EFI=y |CONFIG_EFI=y |
|CONFIG_HIGH_RES_TIMERS |CONFIG_HIGH_RES_TIMERS=y |CONFIG_HIGH_RES_TIMERS=y |
|CONFIG_RCU_NOCB_CPU |CONFIG_RCU_NOCB_CPU=y |CONFIG_RCU_NOCB_CPU=y |
|CONFIG_HUGETLBFS |CONFIG_HUGETLBFS=y |CONFIG_HUGETLBFS=y |
|CONFIG_SCHED_MC_PRIO |Missing |CONFIG_SCHED_MC_PRIO=n |
|CONFIG_PREEMPT_RT |# CONFIG_PREEMPT_RT is not set |CONFIG_PREEMPT_RT=y |
|CONFIG_CPU_FREQ |# CONFIG_CPU_FREQ is not set |CONFIG_CPU_FREQ=n |
|CONFIG_CPU_ISOLATION |CONFIG_CPU_ISOLATION=y |CONFIG_CPU_ISOLATION=y |
|CONFIG_MIGRATION |CONFIG_MIGRATION=y |CONFIG_MIGRATION=y |
|CONFIG_PCIEPORTBUS |CONFIG_PCIEPORTBUS=y |CONFIG_PCIEPORTBUS=y |
----------------------------------------------------------------------------------------------------------------------------------------------------------
Kernel configuration check finished.
Real-Time Performance Test#
This module contains the following benchmarks to evaluate the performance of the target system:
Interpret Real-Time Performance Test Results
Click to show RTPM example output
=============================Real-Time PERFORMANCE TEST Mon Dec 1 00:00:02 UTC 2021=============================
Real-time task CPU affinity is set to core 1 by default. Stress is added to other CPU cores if enabled. It's recommended to isolate the core 1 for real-time task from others.
To change the default test duration. Please modify test_cfg file.
Calculating Stress workload running duration...
Setup stress on core 0
Setup stress-ng on core 2
Setup hackbench on core 3
>>> Processing latency...Test duration: 21600s
>>> Latency Test Command: taskset -c 1 /opt/benchmarking/rhealstone/latency -c 1 -p 250 -T 21600 -s -g /tmp/rtpm/latency_test_1643673592.log
# 06:00:00 (periodic user-mode task, 250 us period, priority 99)
# ----lat min|----lat avg|----lat max|-overrun|---msw|
# 7.924| 9.728| 60.457| 0| 0|
7 1
7.5 72
8.5 10063785
9.5 49405401
10.5 22821895
11.5 1447656
...
>>> Processing cyclictest...Test duration: 21600s
>>> Current cyclictest version: cyclictest V 1.00
>>> Cyclictest Test Command: taskset -c 1 cyclictest -p 99 -i 250 -m -a 1 -N -o 3970 -v -r -q -n -D 21600
Max CPUs = 4
# /dev/cpu_dma_latency set to 0us
Thread 0 Interval: 750
Thread 0 using cpu 1.
0: 0: 16319
0: 4449: 16103
0: 10551: 9183
0: 13394: 15544
...
T: 0 (1181838) P:99 I:250 C:85141567 Min: 2910 Act: 3675 Avg: 3627 Max: 20109
>>> Processing msi_latency test...Test duration: 60s
Msi-latency test finish, max:3936 ns, avg:2682 ns, min:2464 ns
>>> Processing msi_jitter test...Test duration: 60s
Msi-jitter test finish, max:1552 ns, avg:304 ns, min:0 ns
>>> Processing rhealstone...Test cycles: 2
>>> Rhealstone Test Command: Cycle 'taskset -c 1 /opt/benchmarking/rhealstone/ctx_lat' 2 times and calcuate the average value
>>> Rhealstone Test Command: Cycle 'taskset -c 1 /opt/benchmarking/rhealstone/deadlock_bt' 2 times and calcuate the average value
>>> Rhealstone Test Command: Cycle 'taskset -c 1 /opt/benchmarking/rhealstone/preempt_lat' 2 times and calcuate the average value
>>> Rhealstone Test Command: Cycle 'taskset -c 1 /opt/benchmarking/rhealstone/semaphore_lat' 2 times and calcuate the average value
[1777.43, 1753.55]
[1777.43, 1753.55]
ctx_sum is 3530.98
ctx_avg is 1765.49
[6895.52, 6299.76]
[6895.52, 6299.76]
dead_sum is 13195.280000
dead_avg is 6597.640000
[3626.61, 5100.095]
[3626.61, 5100.095]
sem_sum is 8726.705000
sem_avg is 4363.352500
[6762.415, 6823.44]
[6762.415, 6823.44]
pree_sum is 13585.855000
pree_avg is 6792.927500
>>> Processing mmio_latency test...Test memory region: 7fe00000 on Device: 01:00.0, Test duration: 300s
MMIO-Latency test finish, max:14698 ns, avg:4871 ns, min:4186 ns
>>> Processing Caterpillar test...
>>> Caterpillar Command: /opt/benchmarking/caterpillar/caterpillar -c 1 -n 10000 -i 50000 -s 200
Cache Allocation Technology (CAT)erpillar benchmark v1.1
The benchmark will execute an operation function 50000 times.
Samples are taken every 10000 test cycles.
A total of 200 samples will be measured.
Thread affinity will be set to core_id: 1
Timings are in CPU Core cycles
SampleMin: Minimum execution time during the display update interval
SampleMax: Maximum execution time during the display update interval
SmplJitter: Jitter in the execution time during the display update interval
SessionMin: Minimum execution time since the program started or statistics were reset
SessionMax: Maximum execution time since the program started or statistics were reset
SessionJitter: Jitter in the execution since the program started or statistics were reset
Sample: Sample number
Priming cache...
SampleMin SampleMax SmplJitter SessionMin SessionMax SessionJitter Sample
152506 156402 557 152506 156402 557 0
152429 156426 551 152429 156426 554 1
152180 156335 561 152180 156426 556 2
152486 156420 553 152180 156426 556 3
152278 156600 554 152180 156600 555 4
152750 156294 547 152180 156600 554 5
152580 156199 588 152180 156600 559 6
...
>>> Caterpillar test finish, Max session jitter: 584 CPU Cycles
>>> Processing Jitter test...
>>> Jitter Command: /opt/benchmarking/jitter/jitter -c 1 -r 20000 -l 80000 -i 200
Linux Jitter testing program version 1.9
Iterations=200
The pragram will execute a dummy function 80000 times
Display is updated every 20000 displayUpdate intervals
Thread affinity will be set to core_id:1
Timings are in CPU Core cycles
Inst_Min: Minimum Excution time during the display update interval(default is ~1 second)
Inst_Max: Maximum Excution time during the display update interval(default is ~1 second)
Inst_jitter: Jitter in the Excution time during rhe display update interval. This is the value of interest
last_Exec: The Excution time of last iteration just before the display update
Abs_Min: Absolute Minimum Excution time since the program started or statistics were reset
Abs_Max: Absolute Maximum Excution time since the program started or statistics were reset
tmp: Cumulative value calcualted by the dummy function
Interval: Time interval between the display updates in Core Cycles
Sample No: Sample number
Inst_Min Inst_Max Inst_jitter last_Exec Abs_min Abs_max tmp Interval Sample No
158807 158939 132 158809 158807 158939 3158835200 3179339706 1 132
158807 158944 137 158852 158807 158944 2370306048 3179421895 2 137
158807 158938 131 158860 158807 158944 1581776896 3179361092 3 137
158807 158940 133 158840 158807 158944 793247744 3179379386 4 137
158807 158944 137 158843 158807 158944 4718592 3179371249 5 137
...
>>> Jitter test finish, Max inst jitter: 12772 CPU Cycles
>>> Processing LMbench test...
>>> LMbench Command: taskset -c 1 /usr/bin/lat_mem_rd -P 1 128 512
"stride=512
0.00049 1.590
0.00098 1.590
0.00195 1.590
0.00293 1.590
0.00391 1.590
0.00586 1.590
0.00781 1.590
...
>>> LMbench test finish, 1M memory read latency: 13.655 ns
Real-time performance test finished.
To start the benchmark, run the following commands:
Note
Ensure that the RTPM Prerequisites have been completed first.
$ sudo /opt/benchmarking/rtpm/rtpm_exec -p "./output" -n "report.csv" -a
The results are logged in: ./output/rtpm_test.log
RTPM Command Line Parameters#
Parameter |
Explanation |
|---|---|
|
Specify the path of the test file |
|
Specify the test report name in CSV format (must end with |
|
Execute Latency or Cyclictest test when running performance test |
|
Execute Rhealstone test when running performance test |
|
Execute MSI-latency test when running performance test |
|
Execute MSI-jitter test when running performance test |
|
Execute MMIO-Latency test when running performance test |
|
Execute Caterpillar test when running performance test. |
|
Execute Jitter test when running performance test. |
|
Execute LMbench test when running performance test. |
|
Enable stress when running performance test |
|
Execute all performance tests except Latency & Cyclictest, the program will help to identify current Real-Time framework, if it is Xenomai, will run Latency otherwise if it is Preempt-RT, it will run Cyclictest. If not specified, settings in configuration file will be used. |
|
Show the help list |
For more information on using RTPM, refer to the guide.