Intel® Edge AI Sizing Reporting Tool#
Intel® Edge AI Sizing Reporting Tool is a command line tool that is designed to scale AI systems for OxM / Disti and accelerate its deployment with ISV/SI partners. The tool will provide OxM/Disti a general understanding on system capability to undertake AI workloads.
Supported Hardware Platforms#
Intel® Core™ Ultra Processors
Intel® Core™ Ultra Processors (Series 2)
Optional Pairing: Intel® Arc™ B-Series B580 Graphics
Intel® Core™:
11th, 12th, or 13th Generation Embedded processors
12th, or 13th Generation Desktop processors with Intel® Arc™ A380 Graphics
Intel® Xeon®:
4th, or 5th Generation Scalable Processors
Optional Pairing: Intel® Arc™ A380 Graphics
How It Works#
Intel® Edge AI Sizing Reporting Tool is a software package that allows customers to test and qualify system for specific AI usecases such as computer vision, natural
language processing, and audio processing. This is to ensure the system capabilities of handling the required workloads and performance metrics for AI applications.
It is to provides assurance of the system’s quality and reliability to run AI system among users and within the broader ecosystem.
After installation, user can run the test cases with a single command and test results will be stored in the output file. Edge AI Sizing Reporting Tool generates a complete test report in HTML format and detailed logs packaged as one ZIP file, which you can email to the Intel® ESQ support team at edge.software.device.qualification@intel.com.
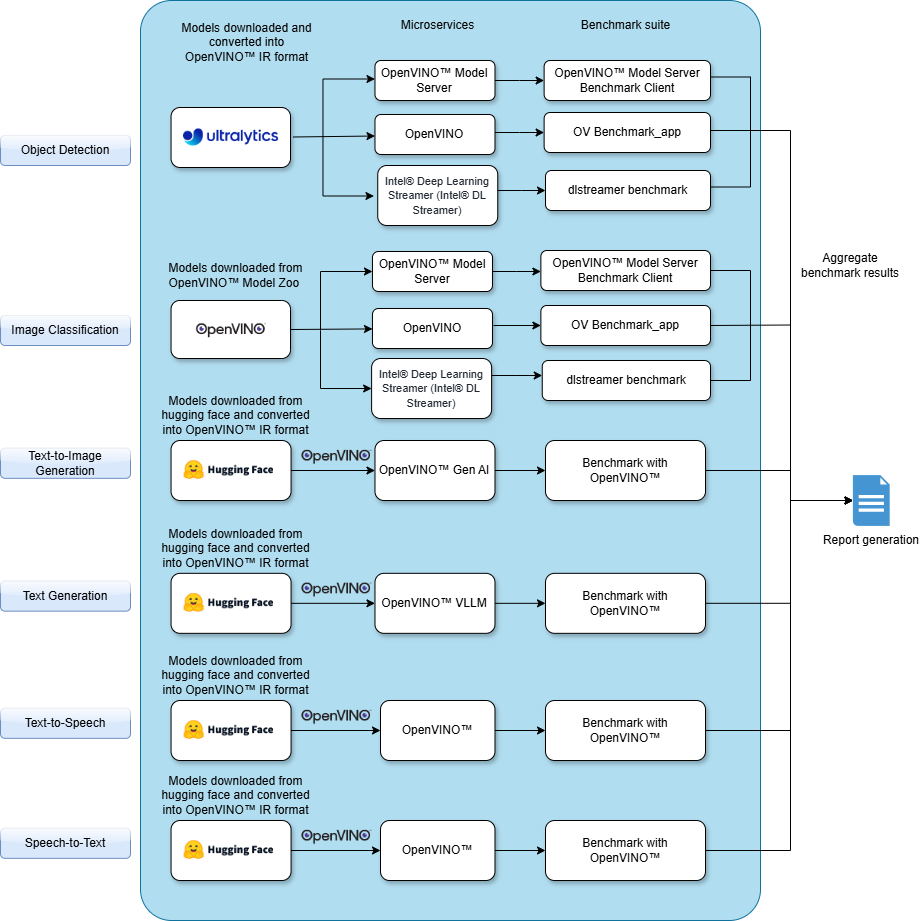
Benchmark Modules#
Computer Vision - Object Detection#
Object detection utilizes OpenVINO™ Model Server (OVMS) and the DL Streamer pipeline to deploy models optimized for Intel® architectures. The DL Streamer pipeline integrates GStreamer elements to process video streams efficiently, enabling real-time inference for object detection tasks. The OVMS benchmark client is employed to interact with the model servers and evaluate the performance of the models hosted by OVMS. Performance metrics such as frames per second (FPS) and average latency (ms) are recorded over a 60-second period by serving synthetic data in a loop through the dataset. Additionally, the number of streams that can sustain within the target FPS is determined by incrementally increasing the number of concurrent streams until the FPS falls below the target threshold.
Object Detection Benchmark#
This section outlines the methodology used for benchmarking object detection models using OpenVINO™ Model Server’s (OVMS) benchmark client and the DL Streamer pipeline.
Benchmark Models#
The following is the model included in the benchmark:
Model Name |
|---|
YOLO11n |
Methodology#
The benchmark process involves the following steps:
1. Model Selection#
The model specified in the list above is optimized and exported into OpenVINO™ IR format.
2. Dataset Preparation#
The dataset is generated by first downloading metadata from the server, which includes a list of available models, their versions, and the accepted input and output shapes. Using this information, the client creates tensors filled with random data that match the shapes required by the models served by the service. The length of the dataset and the duration of the workload can be specified independently, and the synthetic data is served in a loop over the dataset until the specified workload duration is met.
3. DL Streamer Pipeline Integration#
The DL Streamer pipeline is configured to process video streams for object detection. The pipeline includes the following stages:
Source Element: Reads video streams or synthetic data.
Decode Element: Decodes the video frames.
Inference Element: Runs inference using the OpenVINO™ IR model.
Post-Processing Element: Applies post-processing to extract bounding boxes, labels, and confidence scores.
Sink Element: Outputs the processed frames or metrics.
The pipeline is executed using GStreamer commands, ensuring efficient video processing and inference.
4. Benchmark Execution#
Run the benchmark script using the OpenVINO™ Model Server’s benchmark client and the DL Streamer pipeline to evaluate the models’ performance by measuring the number of streams supported for the specified target FPS.
Additional Information#
For more details, please refer to the official documentation on OpenVINO™ Model Server (OVMS), Intel® DL Streamer, and its benchmark client.
Computer Vision - Image Classification#
Image classification uses OpenVINO™ Model Server (OVMS) and the DL Streamer pipeline to serve models optimized for Intel® architectures. The DL Streamer pipeline processes video streams for classification tasks, enabling real-time inference. The benchmark client from OVMS is used to communicate with the model servers and measure the performance of the models served by OVMS. Performance metrics include frames per second (FPS) and average latency (ms) measured for 60 seconds by serving the synthetic data created in a loop iterating over the dataset. The number of streams that can sustain within the target FPS is also measured by gradually increasing the number of concurrent streams until the FPS drops below the target FPS.
Object Classification Benchmark#
This section outlines the methodology used for benchmarking image classification models using OpenVINO™ Model Server’s (OVMS) benchmark client and the DL Streamer pipeline.
Benchmark Models#
The following models are included in the benchmark:
Model Name |
|---|
resnet-50-tf |
Methodology#
The benchmark process involves the following steps:
1. Model Selection#
Select the models to be evaluated from the list provided above. Each model has been optimized and exported in OpenVINO™ IR format.
2. Dataset Preparation#
The benchmark client creates the dataset by retrieving metadata from the server that outlines available models, their versions, and the required input and output shapes. Using this information, the client generates tensors with random data that align with the shapes needed by the models provided by the service. The length of the dataset and the workload duration can be independently configured, and the synthetic data is continuously served in a loop over the dataset until the specified workload duration is fulfilled.
3. DL Streamer Pipeline Integration#
The DL Streamer pipeline is configured to process video streams for image classification. The pipeline includes the following stages:
Source Element: Reads video streams or synthetic data.
Decode Element: Decodes the video frames.
Inference Element: Runs inference using the OpenVINO™ IR model.
Post-Processing Element: Applies post-processing to extract classification labels and confidence scores.
Sink Element: Outputs the processed frames or metrics.
The pipeline is executed using GStreamer commands, ensuring efficient video processing and inference.
4. Benchmark Execution#
Run the benchmark script using the OpenVINO™ Model Server’s benchmark client and the DL Streamer pipeline to evaluate the models’ performance by measuring the number of streams supported for the specified target FPS.
Additional Information#
For more details, please refer to the official documentation on OpenVINO™ Model Server (OVMS), Intel® DL Streamer, and its benchmark client.
Computer Vision - Text to Image Generation#
Text-to-image generation in FLUX.1-schnell utilizes OpenVINO™ to deploy models optimized for Intel® architectures. A benchmarking framework interacts with the model servers to assess the performance of text-to-image generation models. Performance metrics, such as the time required to generate an image (in milliseconds), are measured using prompt inputs. FLUX.1-schnell is designed for efficient text-to-image synthesis, leveraging OpenVINO™’s optimized inference capabilities to accelerate model execution and enhance deployment efficiency.
Text to Image Generation Benchmark#
This section outlines the methodology used for benchmarking text-to-image generation models using OpenVINO™ GenAI.
Benchmark Models#
The following is the model included in the benchmark:
Model Name |
|---|
FLUX.1-schnell |
Methodology#
The benchmark process involves the following steps:
1. Model Selection#
The model specified in the list above is optimized and exported into OpenVINO™ IR format.
2. Dataset Preparation#
No specific dataset was provided, but an input prompt was utilized to generate the images.
3. Benchmark Execution#
Run the benchmark script with OpenVINO™ to assess the models’ performance such as time required to generate an image (in milliseconds) using prompt inputs.
Additional Information#
For more details, please refer to the official documentation on OpenVINO™ GenAI. For further information on the model used, please refer to FLUX.1-schnell in Hugging Face.
Natural Language Processing - Text Generation#
Text Generation Benchmark#
This section describes the methodology for evaluating the performance of text generation models using the VLLM engine powered by Intel® OpenVINO™.
Benchmark Models#
The following models are included in the benchmark:
Model Name |
|---|
meta-llama/Llama-3.1-8B-Instruct |
meta-llama/Llama-3.3-70B-Instruct |
Qwen/Qwen2.5-7B-Instruct |
Qwen/Qwen2.5-14B-Instruct |
Qwen/Qwen2.5-32B-Instruct |
google/gemma-2-9b-it |
google/gemma-2-27b-it |
Microsoft/Phi-3.5-mini-instruct |
Methodology#
The benchmarking procedure consists of the following steps:
1. Model Selection#
Choose the models to benchmark from the list provided above. Each model has been optimized and exported in OpenVINO™ IR format.
2. Dataset Preparation#
Utilize the ShareGPT dataset for validation purposes. This dataset is specifically curated to provide a comprehensive evaluation of the models’ performance. More information about the dataset can be found on the Hugging Face dataset page.
3. Benchmark Execution#
Run the benchmark script using the VLLM engine on Intel® CPU and Intel® GPU devices. The script is designed to evaluate the models’ performance across various metrics. The benchmark script can be found in the VLLM project repository.
Additional Information#
For more details on the VLLM engine and its capabilities, please refer to the VLLM project documentation. For further information on the ShareGPT dataset, visit the Hugging Face dataset page
The service used to perform the benchmark can be found in the Intel Edge Developer Kit Reference Scripts
Audio - Text to Speech#
MeloTTS utilizes OpenVINO™ to deploy optimized text-to-speech models on Intel® architectures. A benchmarking framework evaluates performance, measuring audio generation time (ms) using text inputs. Designed for efficiency, MeloTTS leverages OpenVINO™’s optimized inference to accelerate execution and enhance deployment. With its lightweight design, MeloTTS is ideal for AIPC systems, ensuring high performance. This article covers its adaptation for OpenVINO™, enabling deployment across CPUs and GPUs.
Text to Speech Benchmark#
This section describes the methodology for evaluating text-to-speech models using Intel® OpenVINO™.
Benchmark Models#
The following models are included in the benchmark:
Model Name |
|---|
openai/whisper-tiny |
openai/whisper-small |
openai/whisper-medium |
openai/whisper-large-v3 |
openai/whisper-large-v3-turbo |
Methodology#
The benchmarking process involves the following steps:
1. Model Selection#
Choose the models to benchmark from the list provided above. Each model has been optimized and exported in OpenVINO™ IR format.
2. Dataset Preparation#
A sample dataset from librispeech_s5 dataset is downloaded and used to run the benchmark. The dataset can be downloaded in this link.
3. Benchmark Execution#
Run the benchmark script using the VLLM engine on Intel® CPU and Intel® GPU and Intel® NPU devices. The script is designed to evaluate the models’ performance across various metrics, including:
Latency: Measure the time taken to generate speech from the input text.
Additional Information#
The service used to perform the benchmark can be found in the Intel Edge Developer Kit Reference Scripts
Audio - Speech to Text#
Whisper utilizes OpenVINO™ to deploy optimized speech-to-text models on Intel® architectures. A benchmarking framework evaluates performance, measuring transcription time (ms) using audio inputs. Designed for efficiency, Whisper leverages OpenVINO™’s optimized inference to accelerate execution and enhance deployment.
Speech To Text Benchmark#
This section outlines the methodology used for benchmarking speech to text models using Intel® OpenVINO™.
Benchmark Models#
The following models are included in the benchmark:
Model Name |
|---|
MeloTTS |
Methodology#
The benchmarking process involves the following steps:
1. Model Selection#
Choose the models to benchmark from the list provided above. Each model has been optimized and exported in OpenVINO™ IR format.
2. Dataset Preparation#
A sample text: Welcome! I'm here to help with your questions. is used as the prompt for model input.
3. Benchmark Execution#
Run the benchmark script using the VLLM engine on Intel® CPU and Intel® GPU and Intel® NPU devices. The script is designed to evaluate the models’ performance across various metrics, including:
Latency: Measure the time taken to generate speech from the input text.
Additional Information#
The service used to perform the benchmark can be found in the Intel Edge Developer Kit Reference Scripts
Learn More#
Get Started with Intel® Edge AI Sizing Tool: Follow step-by-step instructions to set up the application.
Intel® Deep Learning Streamer (Intel® DL Streamer): Enhance reading on Intel® DL Streamer