Time Series Analytics#
The Time Series Analytics Microservice comprises of the Telegraf* and the Kapacitor* components of TICK(Telegraf, InfluxDB, Chronograf, Kapacitor) Stack running as individual containers to ingest and process the time series data respectively.
Overview#
The Time Series Analytics Microservice’s Kapacitor* component of TICK stack does the processing of the ingested time series data coming from Telegraf* microservice. By default, the Telegraf* and Kapacitor* containers are connected over HTTP with InfluxDB* container from the Data Store microservice.
Programming Language: Golang and Python
How It Works#
Ingestion#
Time Series Analytics Microservice’s Telegraf* container is a customization over the Telegraf* component of TICK stack which is a plugin-based agent having many input and output plugins. It’s being used for data ingestion and sending data to InfluxDB*.
Telegraf starts with the default configuration which is present at [WORKDIR]/IEdgeInsights/Telegraf/config/Telegraf/Telegraf.conf. By default the below plugins are enabled:
MQTT input plugin ([[inputs.mqtt_consumer]])
Influxdb output plugin ([[outputs.influxdb]])
Analytics#
Time Series Analytics Microservice’s Kapacitor* container is a customization over the Kapacitor* component of TICK stack which is a native data processing engine. It can process both stream and batch data from InfluxDB. Kapacitor lets you plug in your own custom logic or user-defined functions to process alerts.
Users can write the custom anomaly detection algorithm also called as UDF (user-defined function) in python or golang, these algorithms follow certain API standards for the Kapacitor to call these UDFs at run time. After fetching the ingested data from Telegraf*, Kapacitor calls the UDF to run the custom anomaly detection algorithm and store the results directly back to InfluxDB* component of Data Store microservice.
Below are some of the default user defind functions (UDFs) that can be referenced in Kapacitor codebase:
UNIX Socket based UDFs
py_classifier.py:Filters the points based on temperature (data <20 and >25 filtered out).
humidity_classifier.py:Filter the points based on humidity (data >25 filtered out)
Process based UDFs
rfc_classifier.py:Random Forest Classification algo sample. This UDF is used for profiling udf as well.
Figure 1: Architecture Diagram
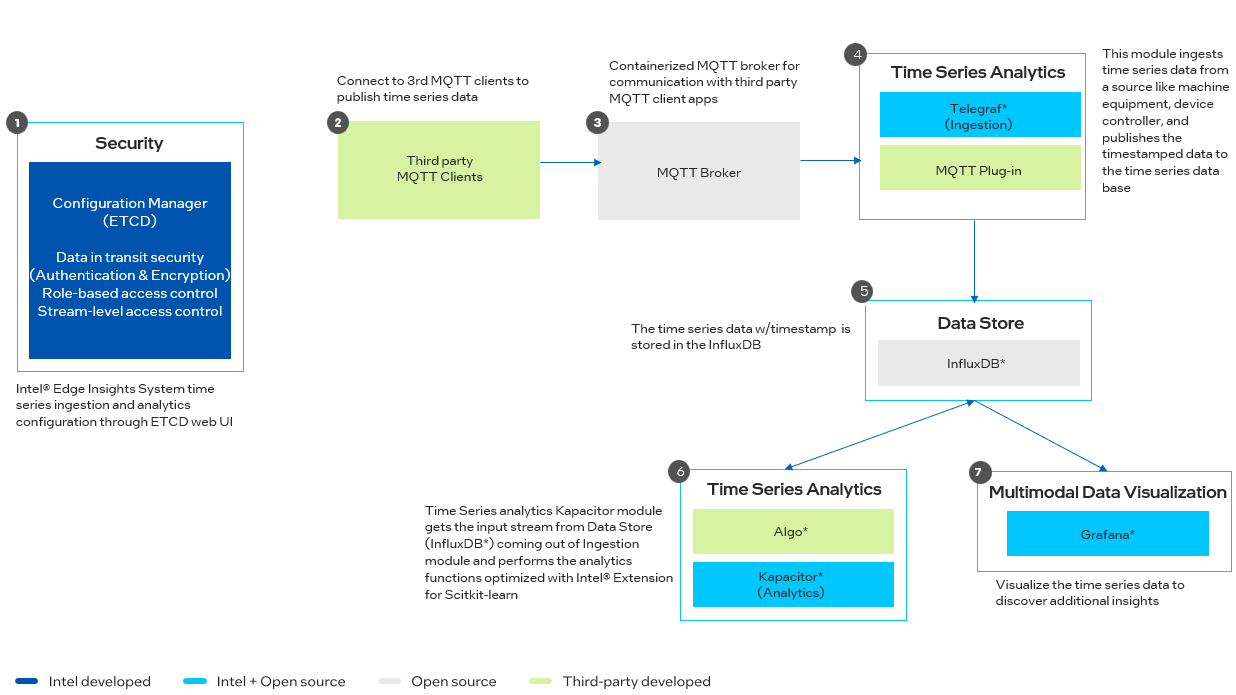
Learn More#
Get started with the microservice using the Get Started Guide.
Follow step-by-step examples to become familiar with the core functionality of the microservice, in Tutorials.